





Content ITV PRO
This is Itvedant Content department
Apply Boosting Techniques (AdaBoost, Gradient Boosting, XGBoost)
Business Scenario
Welcome back!
Today is your seventh day as a Junior Data Scientist on the Telecom Customer Intelligence Project.
In the previous lab, you explored Ensemble Learning using Random Forest and Bagging. Although the model delivered strong results, management wants to evaluate whether Boosting techniques can further improve churn prediction. Unlike Bagging, Boosting learns from previous mistakes to build stronger models.
Your task is to implement AdaBoost, Gradient Boosting, and XGBoost, compare their performance, and identify the most effective model for predicting customer churn.
Pre-Lab Preparation
Topic : Ensemble Learning
1) Boosting (AdaBoost, Gradient Boosting,XGBoost)
2) Sampling techniques
git pull origin branchNameGit Pull
Task 1: Understand Boosting and Apply AdaBoost
Management wants to understand how Boosting differs from Bagging and whether it can improve churn prediction performance.
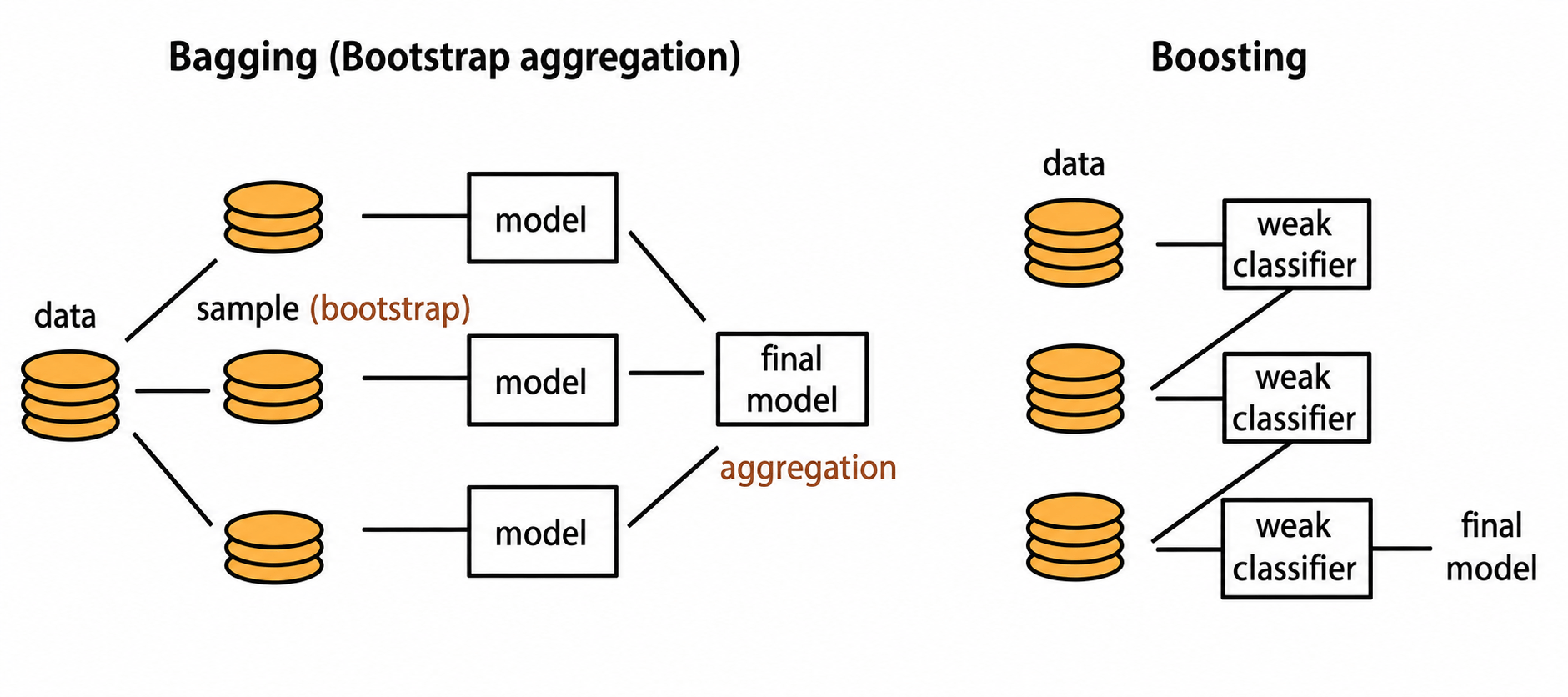
What is Boosting?
Boosting is an Ensemble Learning technique where models are trained sequentially.
Each new model focuses on correcting the mistakes made by previous models.
Unlike Bagging, where models work independently, Boosting builds models one after another to gradually improve prediction accuracy.
What is AdaBoost?
AdaBoost (Adaptive Boosting) is one of the earliest and most popular Boosting algorithms.
It works by building multiple weak learners sequentially and giving higher importance (weights) to observations that were incorrectly classified in previous iterations. This forces each new model to focus more on difficult cases and correct earlier mistakes.
The predictions from all weak learners are then combined to create a stronger and more accurate model.
Create the Model
2
ada_model = AdaBoostClassifier(
n_estimators=100,
random_state=42
)Train the model
3
ada_model.fit(X_train, y_train)Import AdaBoost
1
from sklearn.ensemble import AdaBoostClassifierClick to download previous file : ML Lab 12.ipynb
Make predictions
4
y_pred_ada = ada_model.predict(X_test)Evaluate the Model
5
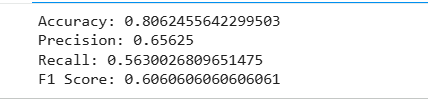
print("Accuracy:",
accuracy_score(y_test, y_pred_ada))
print("Precision:",
precision_score(y_test, y_pred_ada))
print("Recall:",
recall_score(y_test, y_pred_ada))
print("F1 Score:",
f1_score(y_test, y_pred_ada))Management wants to investigate whether a more advanced Boosting approach can better capture customer churn patterns.
Gradient Boosting builds trees sequentially.
Each new tree attempts to reduce the errors made by the previous trees by optimizing a loss function.
This often produces stronger predictive performance than traditional AdaBoost.
What is Gradient Boosting?
Task 2: Apply Gradient Boosting
Import Gradient Boosting
1
from sklearn.ensemble import GradientBoostingClassifierCreate the Model
2
gb_model = GradientBoostingClassifier(
n_estimators=100,
learning_rate=0.1,
random_state=42
)Train the model
3
gb_model.fit(X_train, y_train)Make predictions
4
y_pred_gb = gb_model.predict(X_test)Evaluate the Model
5
print("Accuracy:",
accuracy_score(y_test, y_pred_gb))
print("Precision:",
precision_score(y_test, y_pred_gb))
print("Recall:",
recall_score(y_test, y_pred_gb))
print("F1 Score:",
f1_score(y_test, y_pred_gb))Task 3: Apply XGBoost
Management wants to evaluate an industry-leading Boosting algorithm that is widely used in machine learning competitions and real-world predictive analytics projects.
What is XGBoost?
XGBoost (Extreme Gradient Boosting) is an advanced implementation of Gradient Boosting.
It provides:
Faster training
Better optimization
Regularization to reduce overfitting
High predictive performance
XGBoost is one of the most popular algorithms used in industry for structured data problems.
Install and Import XGBoost
1
!pip install xgboost
from xgboost import XGBClassifierCreate the Model
2
xgb_model = XGBClassifier(
n_estimators=100,
learning_rate=0.1,
random_state=42)Train the Model
3
xgb_model.fit(X_train, y_train)Generate Predictions
4
y_pred_xgb = xgb_model.predict(X_test)Evaluate the Model
5
print("Accuracy:",
accuracy_score(y_test, y_pred_xgb))
print("Precision:",
precision_score(y_test, y_pred_xgb))
print("Recall:",
recall_score(y_test, y_pred_xgb))
print("F1 Score:",
f1_score(y_test, y_pred_xgb))
Great job!
You have successfully completed Lab 13: Apply Boosting Techniques (AdaBoost, Gradient Boosting, XGBoost).
In this lab, you have: Understood Boosting, built AdaBoost, Gradient Boosting, and XGBoost classification models, evaluated their performance using classification metrics, and explored advanced Ensemble Learning techniques for customer churn prediction.
You are now ready to explore customer segmentation using clustering, where you will identify groups of customers with similar characteristics and generate valuable business insights for targeted decision-making.
Checkpoint
Git Push
git push origin branchNameNext-Lab Preparation
Topic : Unsupervised Learning
1) Clustering-based Customer Segmentation (K-Means, Hierarchical Clustering)
By Content ITV




